실전 카프카 - 11장 카프카 커넥트
핵심 개념

소스 커넥트
데이터 소스와 카프카 사이에서 프로듀서 역할을 합니다.
싱크 커넥트
카프카와 타겟시스템 사이에서 컨슈머 역할을 합니다.
내부 동작
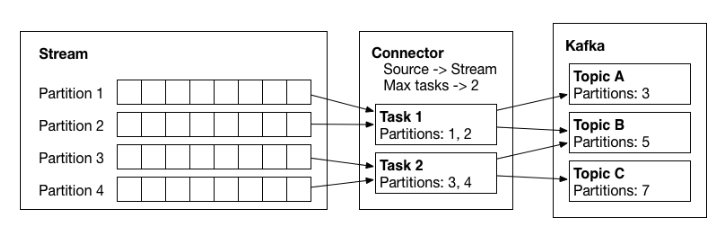
Partitioning (파티셔닝)
커넥터에 복사되어야 하는 데이터들은 레코드 순서에 맞추어 파티셔닝 됩니다.
커넥트에서 나눈 파티션은 카프카 파티션과 용어만 같을 뿐입니다.
Tasks (태스크)
커넥터가 병렬로 실행될 수 있도록 여러 태스크(Task)로 나뉩니다.
커넥터가 여러 태스크로 분할되면 병렬 작업을 통해 성능을 개선할 수 있습니다.
Topic (토픽)
태스크들은 다수의 토픽으로 전송됩니다.
Connect Converter (커넥트 컨버터 )
소스 -> 카프카로 전달할 때 직렬화(serialization)
카프카 -> 싱크로 전달할 때 역직렬화(deserialization) 을 실행합니다.
커넥트에서는 컨버터를 통해 데이터를 전송하여 효율적입니다.

커넥트 REST API
참조 : https://docs.confluent.io/platform/current/connect/references/restapi.html
Kafka Connect REST Interface for Confluent Platform | Confluent Documentation
Since Kafka Connect is intended to be run as a service, it also supports a REST API for managing connectors. By default, this service runs on port 8083. When executed in distributed mode, the REST API is the primary interface to the cluster. You can make r
docs.confluent.io
단일 모드 예제
가장 구현하기 쉬운 파일 커넥터를 통해 예제를 실행
소스 파일 생성
echo "hellow_1" > test.txt
echo "hellow_2" >> test.txt
echo "hellow_3" >> test.txt
cat test.txt
>>>
hellow_1
hellow_2
hellow_3파일 커넥터 설정
cat /usr/local/kafka/config/connect-file-source.properties
>>>
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=connect-test- name : 커넥터에서 식별하는 이름
- connector.class : 커넥터에서 사용하는 클래스
- tasks.max : 실제 작업을 처리하는 태스크의 최대 수
- file : 읽을 파일
- topic : 데이터 전송할 토픽
단독 모드 카프카 커넥트 설정
cat /usr/local/kafka/config/connect-standalone.properties
>>>
bootstrap.servers=localhost:9092
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000- bootstrap.servers : 브로커 주소 지정
- key.converter / value.converter : 데이터를 보내거나 가져올 때 사용하는 포맷을 지정
- offset.storage.file.filename : 재처리 목적으로 오프셋을 파일로 저장할 경로
- offset.flush.interval.ms : 플러시 주기
# File Source Connector 실행 ( REST 요청으로 등록 )
sudo /usr/local/kafka/bin/connect-standalone.sh \
-daemon /usr/local/kafka/config/connect-standalone.properties \
/usr/local/kafka/config/connect-file-source.properties
# REST API로 상태 확인
curl http://localhost:8083/connectors/local-file-source | python -m json.tool
# FIle Sink Connector 실행 ( Connector 설정 파일로 등록 )
sudo curl --header "Content-Type: application/json" \
--header "Accept: application/json" \
--request PUT \
--data '{ "name":"local-file-sink", "connector.class":"FileStreamSink", "tasks.max":"1", "file":"/home/ec2-user/test.sink.txt", "topics":"connect-test"}' http://localhost:8083/connectors/local-file-sink/config
# REST API로 상태 확인
curl http://localhost:8083/connectors/local-file-sink | python -m json.tool파일 커넥터 로그 확인
# file connector topic 생성 확인
sudo /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
>>>
__consumer_offsets
connect-test
# sink connector 확인
curl http://localhost:8083/connectors/local-file-source | python -m json.tool
# source connector 확인
curl http://localhost:8083/connectors/local-file-sink | python -m json.tool
# 등록된 connector 리스트 확인
curl http://localhost:8083/connectors | python -m json.tool
# connect log 확인
tail -f /usr/local/kafka/logs/connect.log결과 확인
cat test.sink.txt
>>>
hellow_1
hellow_2
hellow_3
# 종료
sudo pkill -f connect
분산 모드
운영 환경에서는 분산 모드(클러스터) 사용합니다.
단독 모드와의 가장 큰 차이점은 '메타 정보 저장소 위치' 입니다.
분산 모드는 카프카 내부 토픽을 메타 정보 저장소로 활용하여, 워커 중 하나가 장애가 나도 안전하게 운용할 수 있게 합니다.
분산 카프카 모드 설정
bootstrap.servers=kafka_01.com:9092,kafka_01.com:9092,kafka_01.com:9092
group.id=kafka-connect-cluster
key.converter=org.apache.kafka.connect.converters.ByteArrayConverter
value.converter=org.apache.kafka.connect.converters.ByteArrayConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
offset.storage.topic=connect-offsets
offset.storage.replication.factor=3
offset.storage.partitions=25
config.storage.topic=connect-configs
config.storage.replication.factor=3
config.storage.partitions=1
status.storage.topic=connect-status
status.storage.replication.factor=3
status.storage.partitions=5
offset.flush.interval.ms=10000
# 경로
plugin.path=/usr/local/kafka/config- group.id : 컨슈머 그룹의 그룹 아이디와 동일한 개념
- offset.storage.* : 커넥터들의 오프셋 추적을 위해 토픽, 리플리케이션, 파티션 수 설정
- config.storage.* : 커넥터들의 설정을 저장하는 토픽, 리플리케이션, 파티션 수 설정
- status.storage.* : 커넥터들의 상태를 저장하는 토픽, 리플리케이션, 파티션 수 설정
systemd를 이용해 커넥터 실행 설정
[Unit]
Description=kafka-connect
After=network.target kafka-server.target
[Service]
Type=simple
SyslogIdentifier=kafka-connect
WorkingDirectory=/usr/local/kafka
Restart=always
# Kafka Connect 실행 명령
ExecStart=/usr/local/kafka/bin/connect-distributed.sh /usr/local/kafka/config/connect-distributed.properties
ExecStop=/bin/kill -TERM $MAINPID
[Install]
WantedBy=multi-user.target
실행 확인
sudo systemctl start kafka-connect
sudo systemctl status kafka-connect
참조 :
https://docs.confluent.io/platform/current/connect/devguide.html
Guide for Kafka Connector Developers | Confluent Documentation
Developing a connector only requires implementing two interfaces, the Connector and Task. A simple example of connectors that read and write lines from and to files is included in the source code for Kafka Connect in the org.apache.kafka.connect.file packa
docs.confluent.io
https://developer.confluent.io/courses/kafka-connect/how-connectors-work/
How Kafka Connect Works: Integrating Data Between Systems
Learn how Kafka Connect's internal components—connectors, converters, and transforms—help you move data between Kafka and your sources and sinks.
developer.confluent.io