DataPipeline/Nifi
Apache Nifi - Kafka to HBase
wave35
2023. 3. 24. 07:05
[ 아키텍처 ]
Kafka -> Nifi -> HBase -> Python으로 데이터 Fetch
[ Kafka ]
카프카의 토픽명과 컨슈머그룹명을 정해 데이터를 받는다.
[ Nifi ]
아래와 같은 프로세스 플로우로 구성할 수 있다.
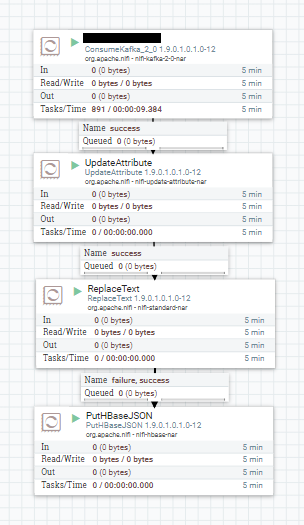
- ConsumerKafka에 토픽명과 그룹명을 설정값으로 입력한다
- UpdateAttribue와 ReplaceText는 해당 데이터가 나이파이에 적제되는 시간을 입력하기 위함이므로 생략가능하다.
- PutHBaseJson에 HBase TableName, Row Identifier, Column Family값을 입력한다.
- 네임스페이스가 있다면 NS:TableName과 값이 입력한다.
- Row Identifier값은 로우키가 되므로 유니크한 값으로 설정한다. 예시에선 $(createdAt}_${uuid}값으로 설정하였다.
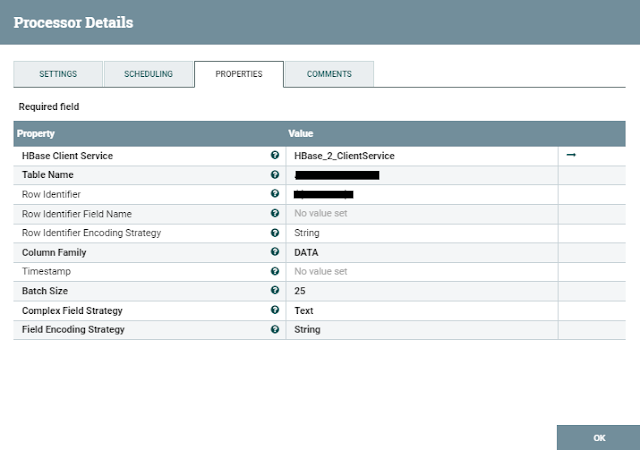
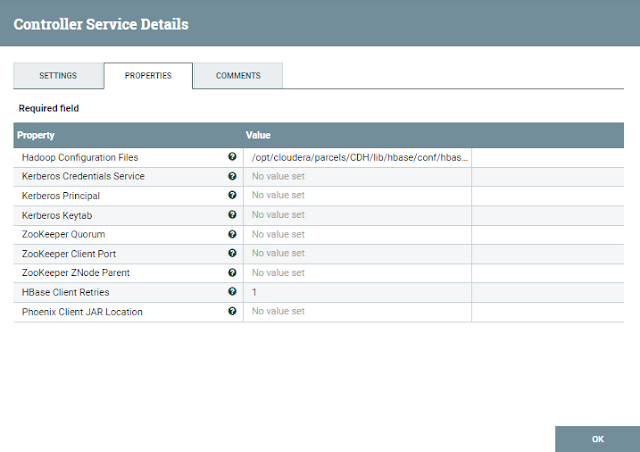
HBase Client Service는 새로 생성한다.
예제는 클라우데라 매니저를 사용하므로
- /opt/cloudera/parcels/CDH/lib/hbase/conf/core-site.xml,
- /opt/cloudera/parcels/CDH/lib/hbase/conf/hbase-site.xml
값을 입력한다.
[ HBase ]
Kafka데이터를 받을 Hbase테이블을 생성한다
$ bin/hbase shell
shell) create 'NS:TableName', 'ColumFamily'
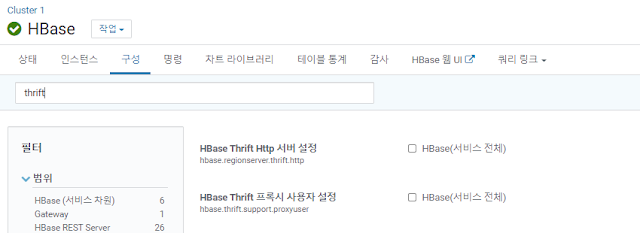
[ HBase 설정 ]
아래 두 설정 값은 False로 두자
[ Python ]
파이썬에서 HBase API를 제공해주는 라이브러리를 설치한다.
$ pip install happybase
간단히 특정날짜의 HBase데이터를 가지고 와, List로 return하는 예제를 작성하였다.
import happybase
# connect
def connOpen() :
conn = happybase.Connection(host='12.345.67.88', port=9090,
table_prefix='NS',
table_prefix_separator=b':',
timeout=None,
autoconnect=False,
transport='framed',
protocol='compact'
)
return conn
def connClose(conn) :
conn.close()
# fetch
def fetchTwoDay(conn, startDate, endDate) :
conn.open()
table = conn.table('Table_Name')
data = table.scan(row_start=startDate, row_stop=endDate)
return list(data)
# USE CASE
#conn = connOpen()
#data = fetchTwoDay(conn, '2021-02-19', '2021-02-21')
#connClose(conn)
#print(data)
- 해당 라이브러리는 Hbase Thrift 서버와 연결하기 때문에
기본 9000, Thrift2는 9090포트값을 설정 값으로 입력한다.
참고 URL :
https://my-bigdata-blog.blogspot.com/2017/04/nifi-to-hbase.html
happybase API URL :
https://happybase.readthedocs.io/en/latest/